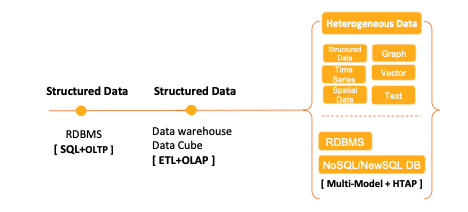
數據庫系統(tǒng)是現代信息社會的基石,其演進歷程深刻反映了計算模式、業(yè)務需求和技術創(chuàng)新的變遷。特別是在支持在線數據處理(OLAP)與在線交易處理(OLTP)這兩類核心業(yè)務的過程中,數據庫技術經歷了從單一到分離,再到融合與創(chuàng)新的螺旋式發(fā)展。
第一階段:關系型數據庫的興起與OLTP的統(tǒng)治(1970s-1990s)
數據庫系統(tǒng)的現代演進始于關系模型的提出。以IBM的System R和加州大學的INGRES為代表,關系型數據庫管理系統(tǒng)(RDBMS)憑借其嚴謹的數學基礎(關系代數與演算)、清晰的結構(表、行、列)和非過程化的查詢語言(SQL),迅速成為主流。這一時期,數據庫的核心使命是高效、可靠地處理企業(yè)的日常業(yè)務交易,即在線交易處理(OLTP)。OLTP業(yè)務的特點是高頻、短小、原子性的讀寫操作(如銀行轉賬、訂單錄入),強調數據的一致性(C)、事務的原子性(A)、隔離性(I)和持久性(D),即嚴格的ACID屬性。技術焦點集中在鎖機制、日志恢復和緩沖區(qū)管理上,以保障在并發(fā)訪問下數據的準確無誤。代表性的商業(yè)數據庫如Oracle、DB2、SQL Server均在此階段奠定霸主地位,架構上多為垂直擴展的單體系統(tǒng)。
第二階段:數據倉庫的誕生與OLAP的分離(1990s-2000s)
隨著企業(yè)數據量的積累,管理層不再滿足于僅處理當前交易,更希望從歷史數據中分析趨勢、輔助決策。這催生了在線分析處理(OLAP) 需求。OLAP業(yè)務涉及對海量歷史數據的復雜查詢、多維度聚合和批量計算(如季度銷售報表、客戶行為分析),特點是查詢復雜、數據掃描量大、但時效性要求相對寬松。
直接將OLAP查詢運行在OLTP數據庫上會產生嚴重沖突:復雜的分析查詢會消耗大量I/O和CPU資源,長時間鎖表,進而拖垮關鍵的交易業(yè)務。為此,數據倉庫(Data Warehouse) 概念應運而生。其核心思想是架構分離:將OLTP系統(tǒng)產生的業(yè)務數據,通過ETL(抽取、轉換、加載)過程,定期導入一個獨立的、針對分析優(yōu)化的數據庫中。這個分析數據庫采用不同的數據模型(如星型模式、雪花模式),并利用預計算(如物化視圖)、列式存儲(早期探索)和專門的索引技術來加速查詢。這一階段,數據庫系統(tǒng)在功能上出現了清晰的讀寫分離和庫倉分離,Teradata、Netezza等專用數據倉庫設備獲得成功。
第三階段:互聯(lián)網時代與NoSQL/NewSQL的沖擊(2000s-2010s)
Web 2.0和移動互聯(lián)網的爆發(fā)帶來了數據特征的劇變:數據量(Volume)、速度(Velocity)、多樣性(Variety)的“3V”挑戰(zhàn)。傳統(tǒng)關系數據庫在應對海量用戶并發(fā)、半結構化/非結構化數據存儲、以及需要跨數據中心分布時顯得力不從心。
為了滿足可擴展性和靈活性,NoSQL數據庫浪潮興起。它們通常犧牲嚴格的ACID事務(追求最終一致性BASE理論)和復雜SQL功能,以換取水平擴展、高可用性和靈活的數據模型(鍵值對、文檔、列族、圖)。這類數據庫很好地支撐了互聯(lián)網規(guī)模的OLTP類應用(如用戶會話、商品目錄、社交圖譜)。為了兼顧SQL的易用性與NoSQL的可擴展性,NewSQL數據庫出現,它們試圖在分布式架構下重新實現ACID事務,例如Google Spanner、CockroachDB。
在OLAP領域,Hadoop生態(tài)(HDFS, MapReduce, Hive)利用廉價硬件集群處理超大規(guī)模數據分析,但其批處理模式延遲較高。MPP(大規(guī)模并行處理) 架構的數據倉庫/數據湖解決方案(如Amazon Redshift, Google BigQuery, Snowflake)將云與列式存儲結合,提供了強大的彈性OLAP能力。
第四階段:云原生、混合負載與實時化的融合(2010s至今)
當前,數據庫演進進入云原生與智能化時代。業(yè)務需求呈現兩大趨勢:
- 實時決策需求:企業(yè)希望在同一份最新的數據上同時進行交易和實時分析,例如在金融反欺詐中,需要在交易發(fā)生的瞬間進行風險分析。這模糊了OLTP與OLAP的傳統(tǒng)界限。
- 數據價值最大化:減少數據移動和復制成本,實現更簡化的數據架構。
為此,技術發(fā)展呈現融合態(tài)勢:
- 云原生數據庫:如AWS Aurora、Azure SQL Database,將計算與存儲分離,實現彈性伸縮、高可用和按需付費,同時兼容傳統(tǒng)SQL和事務模型。
- HTAP數據庫:混合事務/分析處理(HTAP) 成為重要方向。這類數據庫(如Google Spanner, TiDB, Oracle Autonomous Database)旨在用一個數據庫引擎同時高效處理OLTP和OLAP負載。其關鍵技術包括行列混合存儲、智能數據分區(qū)、以及基于快照隔離的讀寫分離,使得分析查詢可以在不影響事務處理的前提下,訪問一致性的實時數據快照。
- 實時分析數據庫:針對流數據的流處理與批處理的邊界也在模糊,出現了流批一體的架構(如Apache Flink),支持對無限數據流進行實時OLAP。
- AI增強:機器學習被用于數據庫內核的自動優(yōu)化(索引推薦、查詢調優(yōu))、成本預測和自治運維。
數據庫系統(tǒng)的演進,圍繞OLTP與OLAP這兩大業(yè)務支柱,走過了從“一體”到“分離”,再到追求“智能融合”的道路。驅動力量從早期的理論創(chuàng)新、中期的規(guī)模化挑戰(zhàn),發(fā)展到今天的云化、實時化和智能化需求。未來的數據庫將不再是單一功能的系統(tǒng),而是向著融合、自治、多模、云原生的方向發(fā)展,為企業(yè)提供一個能夠無縫支持從實時交易到深度分析的全數據價值鏈處理平臺。